This is the continuation of my last article, Azure Cognitive Search for SharePoint Content – Part 1. In this article, we will see how we can create an index and an indexer for the SharePoint content that we have in Azure Cognitive Search.
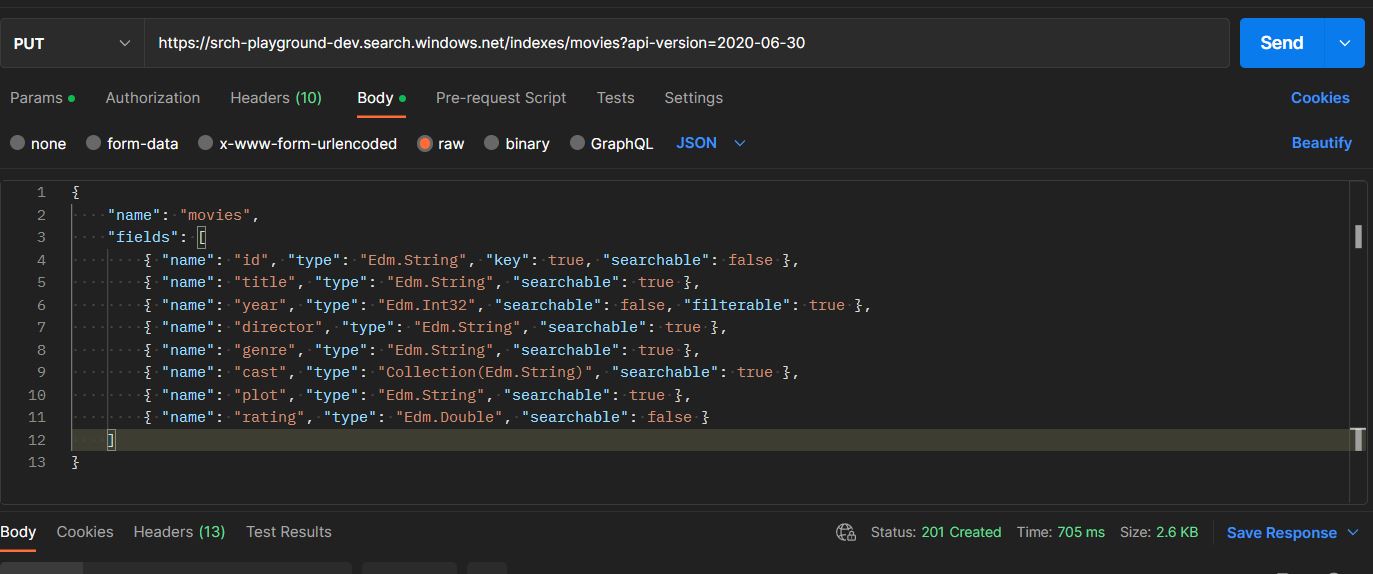
Step 1: Create an index
An index is a data structure that includes all the searchable content. It’s a collection of documents that have been analysed, processed, and organized in a way that allows to search and retrieve relevant information.
An indexer is a process that gets data from external data sources and pushes it into an index. It’s accountable for keeping the index up to date with the newest data from the external data sources.
In my previous article, we discussed about How to Manage Azure Cognitive Search Index using REST API
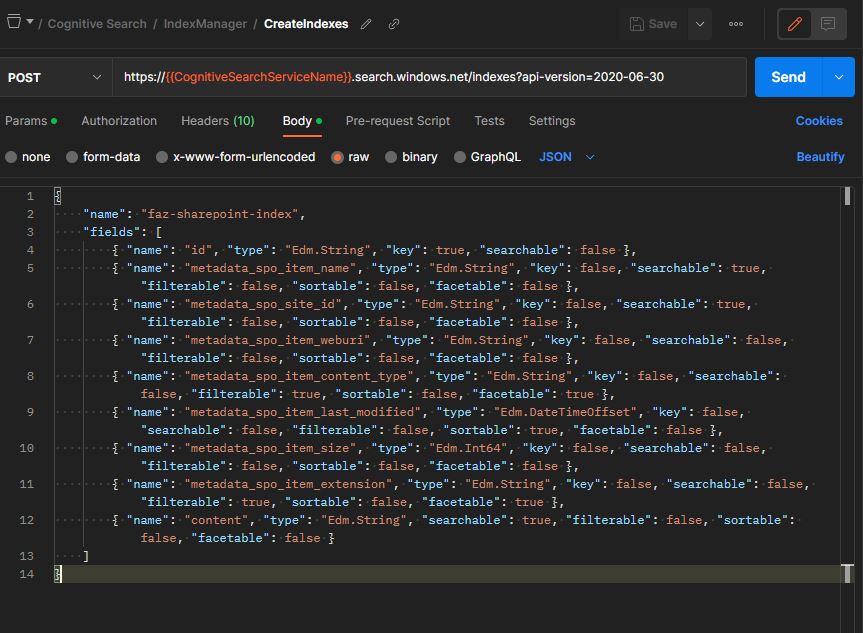
Here you can find the list of metadata that are available for index – https://learn.microsoft.com/en-us/azure/search/search-howto-index-sharepoint-online#indexing-document-metadata
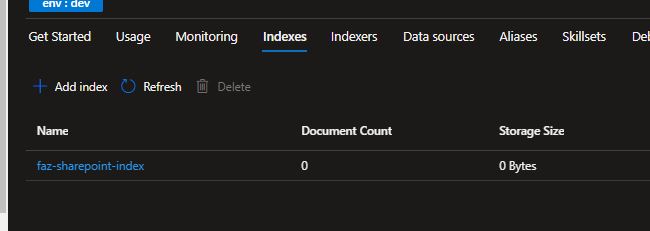
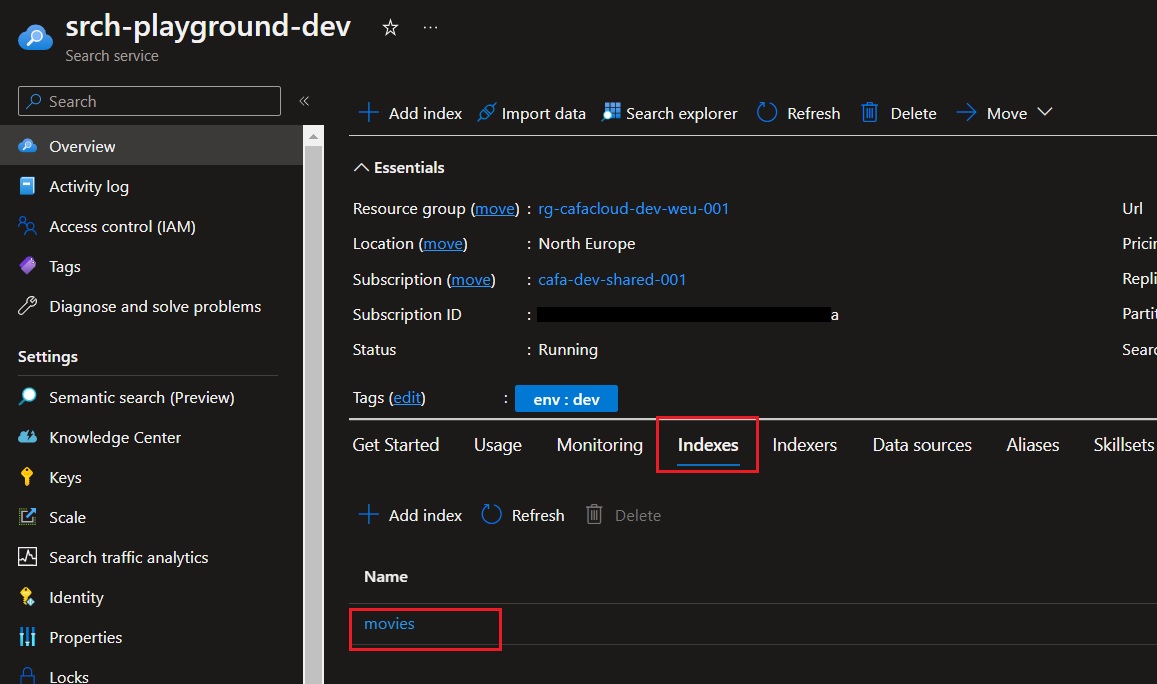
Step 2: Create an indexer
Once the index and data source are created successfully, now we can create indexer which connects both. It can be created using REST API as shown below,
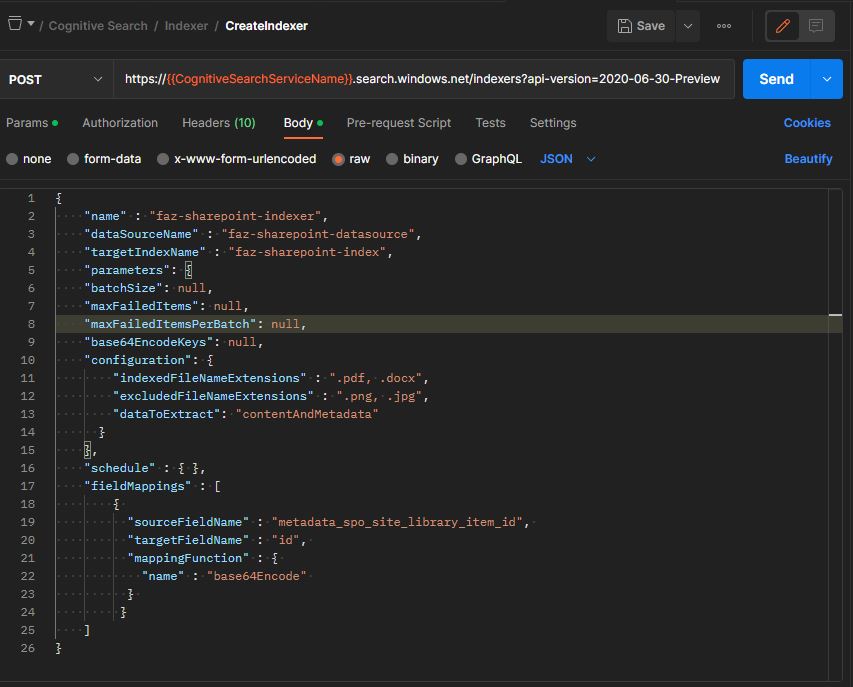
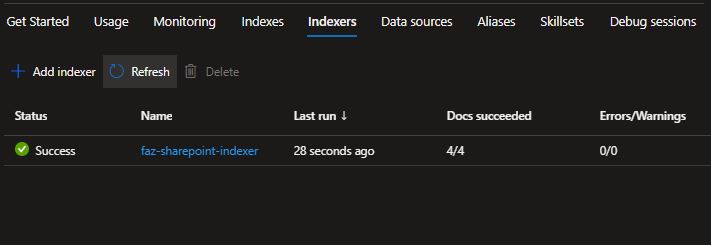
Step 3: Query SharePoint Content
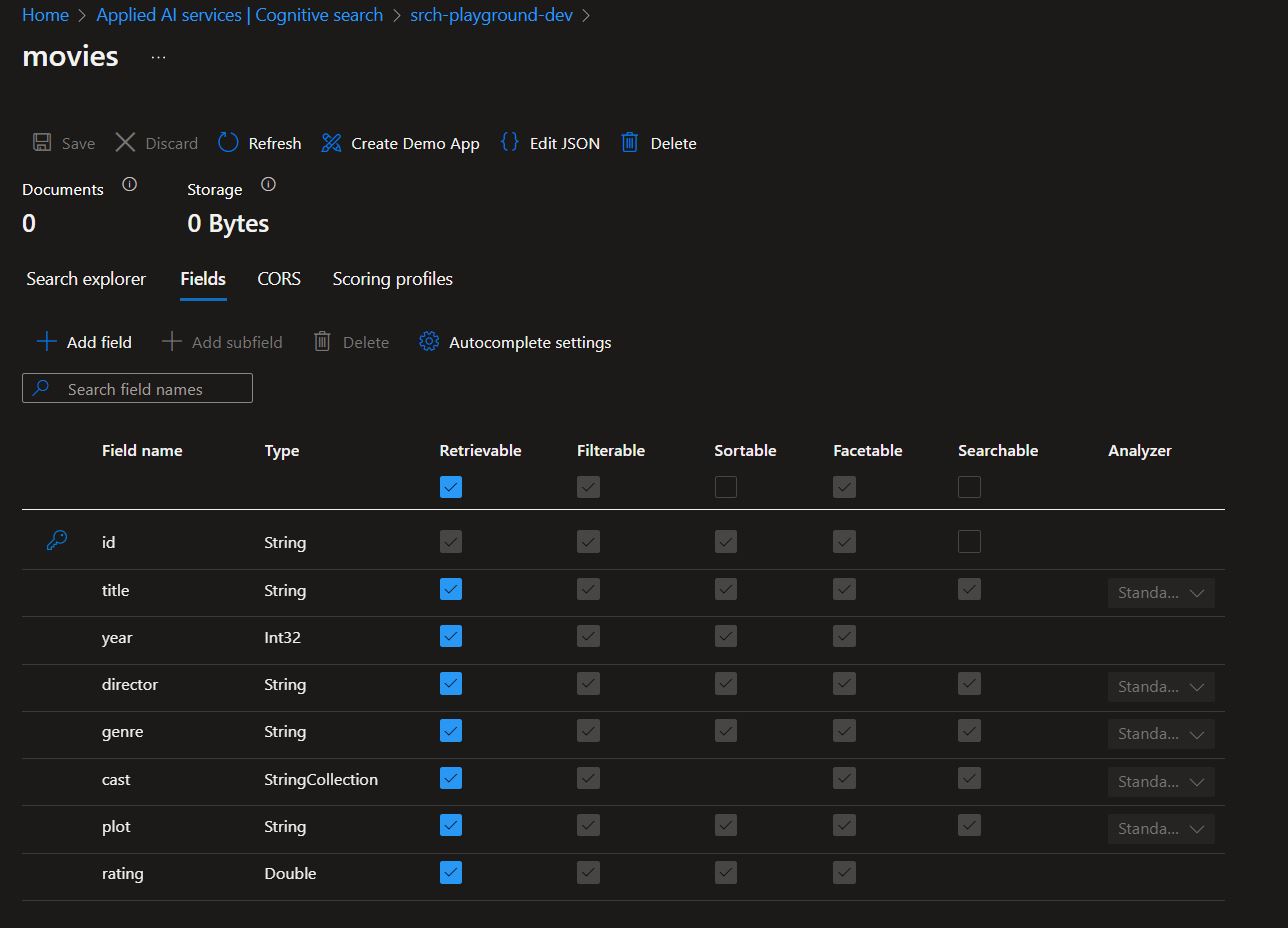
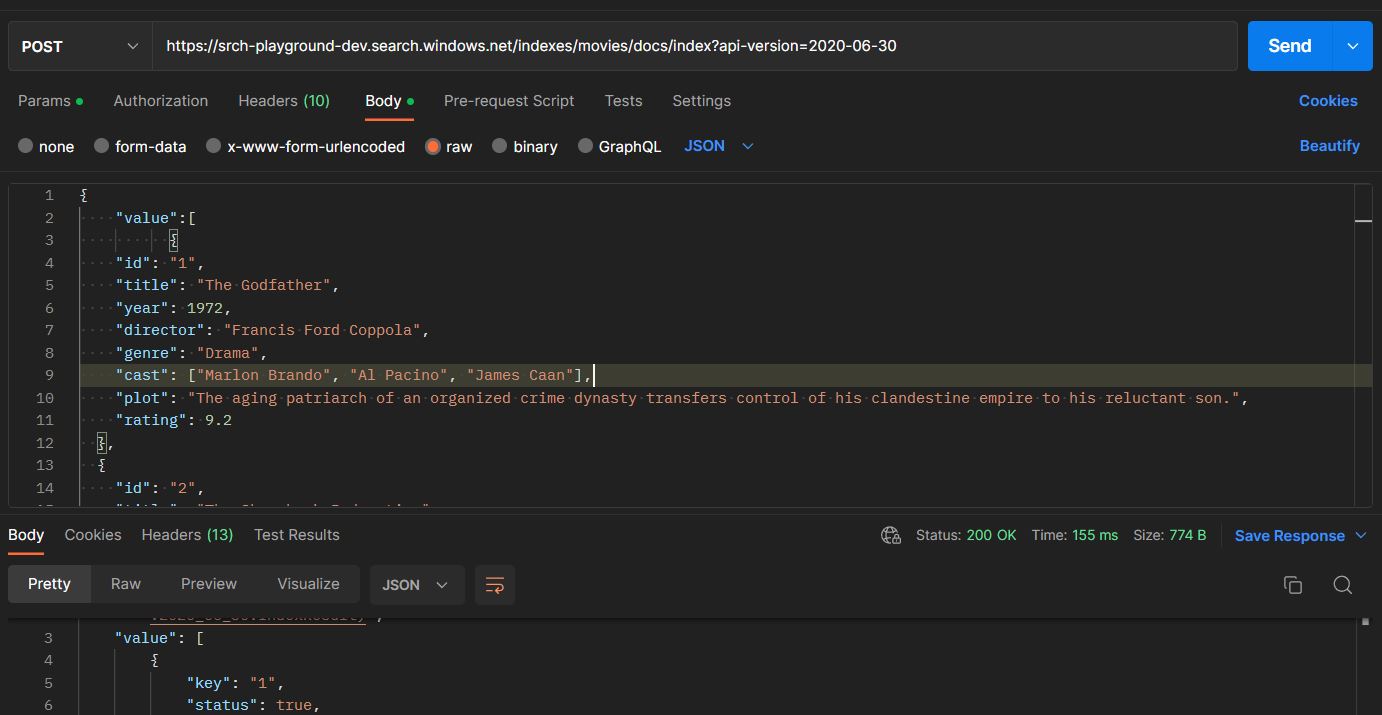
We have finished connecting the SharePoint library with Azure Cognitive Search, and now we can query the SharePoint library content using Azure Cognitive Search. I used the Search Explorer for quick results, and we can already see that the results contain SharePoint library metadata.
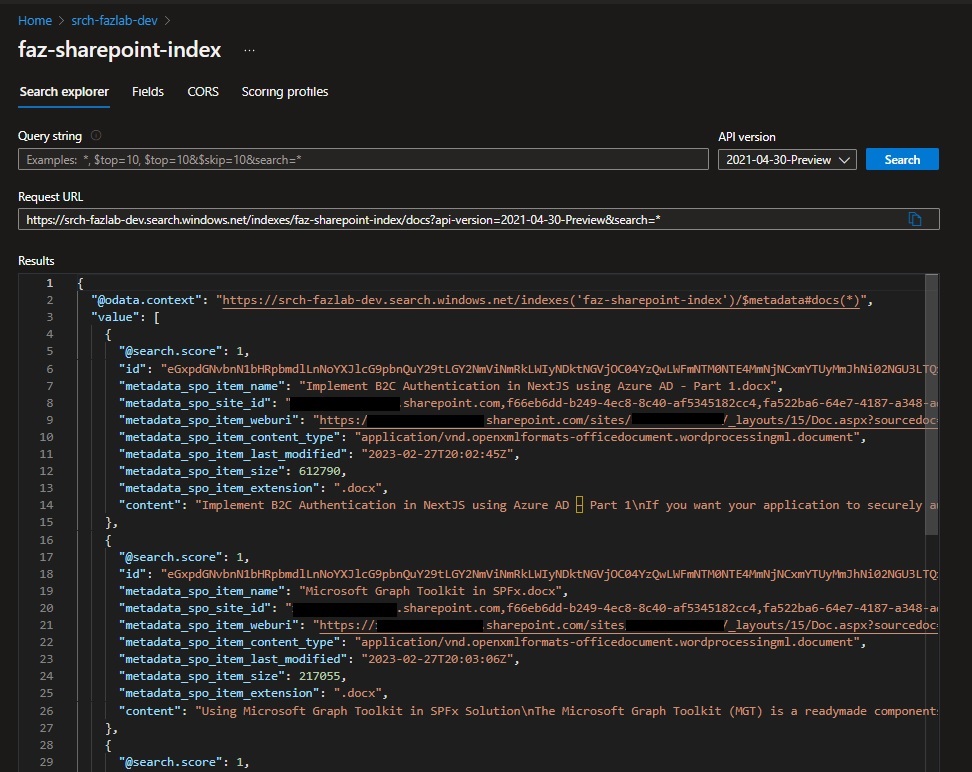
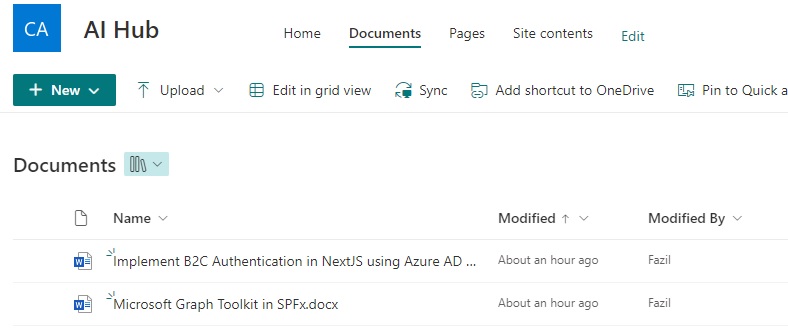
Below, you can see the library content from SharePoint.
In conclusion, Azure Cognitive Search offers a powerful solution for enhancing the search capabilities of SharePoint content. By using advanced techniques like natural language processing and machine learning, organizations can provide more accurate and relevant search results to their users. With easy integration through Azure Cognitive Search API.
We hope this article provided useful insights into how Azure Cognitive Search can enhance the search capabilities of SharePoint content. Thank you for taking the time to read it.
Happy coding,
Fazil




















Leave a comment